
update: 2022/5
この記事を書いた2017年以降の最新の情報をカバーした、音楽生成AIに関するホワイトペーパーをリリースしました。こちらから無償でダウンロードできます。

update: 2021/2
音楽をはじめとした創作活動、創造性とAIの未来像を書いた拙著『創るためのAI—機械と創造性のはてしない物語』がBNNから発売になりました。この記事で書いている内容にも触れています。ぜひお手にとってみてください。
update: 2019/9/25
2019年 4月から慶應義塾大学湘南藤沢キャンパスで 、Computational Creativity Labという名前で研究室をはじめました。AIを使った音楽制作とその技術研究にも精力的に取り組んでいます。興味のある学生はぜひ私の研究室へ!! 詳しくはこちらの記事をご参照ください。
概要
コンピュータで自動的に音楽を生成するという夢は、コンピュータそのものの歴史と同じくらい古くまで遡ることができます。広義での人工知能(AI)を用いた音楽生成も、アルゴリズム作曲/自動作曲として古くから試されてきました。一方で昨今AIに注目が集まるおおきなきっかけともなったDeep Learningを音楽生成に用いた例は、実はまだそれほど多くはないようです。今回、そうしたDeep Learningを音楽の「生成」に用いた研究例を、その手法、入出力のデータ、モデルのアーキテクチャ、学習の戦略などをもとに分類、結果として生成された音楽ととともにまとめたいと思います。
なおこの記事は、以下の素晴らしいサーベイの内容を参考に、筆者(徳井)が解釈・まとめたものです。このサーベイに取り上げられなかった例を一部加筆したほか、割愛しているものもあります。この領域の現状を知る上で簡潔かつ網羅的にまとめられているだけでなく、今後の研究の方向性の示唆も随所に散りばめられているので、この領域に興味のある方は一読されることをオススメします。
Briot, J.-P., Hadjeres, G., & Pachet, F. (2017). Deep Learning Techniques for Music Generation — A Survey.
ここではこの領域の概要をひととおり押さえることを目的にしているので、元のサーベイにあった技術情報の一部はごそっと割愛しています。詳しく知りたい方は上記のサーベイ、あるいは原論文にあたっってください。音楽理論に関してはあまり詳しくないので、もしかしたら単語の使い方がおかしいところがあるかもしれません。変なところを見つけたらぜひご指摘ください!
ちなみに、Deep Learningを用いた音楽の「解析」についてはこちらのチュートリアルがよくまとまっています。参考まで。
Choi, K., Fazekas, G., Cho, K., & Sandler, M. (2017). A Tutorial on Deep Learning for Music Information Retrieval. Retrieved from http://arxiv.org/abs/1709.04396
Deep Learningを音楽の「生成」に用いた研究例を、その手法、入出力のデータ、モデルのアーキテクチャ、学習の戦略などをもとに分類、結果として生成された音楽ととともにまとめる
評価軸
目的 Objective
まずは研究例を分類する上で考慮する必要のあるいくつかの評価軸について整理しましょう。まずは生成の対象、目的 (Objective)からです。「音楽」を生成とひとことに行っても生成の対象はいくつか考えられます。
- メロディー
- ハーモニー
- 伴奏 / コード進行
- リード・シート (ジャズ等で使われるメロディーと和音、歌詞のみを書き起こした記法)
- リズム
これまでのところ多くの研究はやはりメロディーやハーモニーの生成を対象にしているようです。確立した理論があり、コンピュータで扱いやすいために伝統的に研究が進んできた領域と言えるでしょう。
生成システムに対する入力・出力もさまざまです。メロディーのフレーズを入力する場合もあれば、一音だけを入力する、あるいは入力がない場合もあります。出力は、MIDI信号やオーディオが一般的ですが、楽譜を出力してそれを人が演奏する場合もあります。
また音楽生成時の「自律性」も一つのポイントです。生成時にユーザの入力を受け入れるのか、それとも完全に自律的・自動的に生成するのか. ユーザが生成の方向づけをする(ナビゲートする)ようなシステムも考えられますし、ジャズのかけあいを目指すようなシステムの場合は、相手の演奏の情報が入力として扱われることになるでしょう。
表現 Representation
AIに限らずコンピュータで音楽を扱う場合、その情報をどのように「表現」(Representation)するかがひとつのポイントになります。AIでの音楽生成を考えた場合、
- 学習に使うデータ
- 生成時に入力されるデータ
- 生成され出力されるデータ
この三つそれぞれをどう表現するかで、バリエーションが考えられます。またこれらの表現は上記の目的とも密接に関わってきます.
- 音声信号 Audio Signal
音楽をあつかうのであれば、音声信号を扱うのが一番自然だと思われるでしょう。ご存知のようにCDでは一秒間に44100回、音の圧力を16bit(約32000段階)でサンプリングすることで、音を表現しています。忠実に音楽を表現できる一方で、(少なくとも)計算コストが高すぎるため、現状ではまだあまり広く使われていません。その数すくない例ともいえるGoogle/DeepMindのWaveNetでは、1秒間の音(しかも16k, 8bit)を生成するのに、Googleの速いマシンをつかっても数分かかったそうです(最近になって大幅に短縮されたそうですが)。
今後の研究で、大きな躍進が見られるとしたらこの分野かもしれません。WaveNetのように波形をゼロから生成するのではなく、音の素材を組み合わせるような方向性も考えられると思います。
2. 記号 Symbolic
2.1 — MIDI
コンピュータ上で楽譜の情報を扱うために開発されたMIDI信号は、古くからコンピュータ音楽の世界で扱われてきました。音の高さ(pitch), 強さ(velocity)、長さ(duration)の情報として、各音符が扱われます。楽譜を比較的忠実に簡潔に表現できるという利点があり、本サーベイの研究でもMIDIを扱う研究は少なくありません。
MIDIは非常に使い勝手のよい音楽表現ですが、楽譜にならない・記述できない音や音楽(例. 微分音など)が多数あることを念頭において使うべきでしょう。
2.2. — ピアノロール Piano Roll
本サーベイのなかで一番多く使われていた表現です。元はオルゴールのための記述法ですが、いわゆるDAW(LogicやAbleton Liveのような音楽制作用のソフトウェア)でMIDIを記述する方法として定着した記述法です。x軸方向に時間、y軸方向にとりうるすべての音のピッチをマッピングしたグリッドとして音楽を扱います。音楽を行列(マトリクス)のように扱うことができるので都合がいい、というのは、プログラミングで配列を扱ったことがある人であれば、なんとなく想像がつくと思います。
ただし、連続する八分音符ふたつと四分音符一つの区別がつかないといったマイナス面もあり、それに対する改善策も提案されています。
2.3. — テキスト Text
すこし意外ですが、テキストで音楽を扱うという研究もみられました。その多くはABC記法という記法を使っています。(ABC記法には単旋律の音楽しか扱えないという限界があります) 。下記はソーラン節をABC記法で書いたもの。
X:1
T:sooranbushi
M:2/4
L:1/8
K:F
C2 DF | A2 GF | A2 GF | G2 FC | D2 FC | D2 D2 | z2 z2 ||
zG AA | GA AA | GA AA | GF D2 | zA, CA, | CD GF | zG AF | DC FD | D z CC |
DF A2| A3 c | G F2 C | D2 D2 | D2 z2||4. — コード Chord
コード進行を生成するシステムの場合、コードをそのまま文字や数字で直接表現(C, D-, E7 etc)する手法あるいは複数の音の組み合わせとして表現する手法の二つが考えられます。
二つめの手法の例として後述するDeepBachシステムでは次のような表現が取られています. 区切り文字|||の間に挟まれているのが一つの和音で、ピッチとフェルマータの有無の二値で表現されます。
(59, False)
(56, False)
(52, False)
(47, False)
|||
(59, True)
(56, True)
(52, True)
(47, True)
|||5. — リード・シート Lead Sheat
JazzやPopsの世界で広くつかわれる記法ですが、研究で使われている例はそれほど多くはありません。

6. — リズム Rhythm
リズムを扱う研究もそれほど多くはないようです。リズムの表現としては、楽器の種類(たとえばキック、スネア、タム、ハイハット、シンバル)などを限定した上で、その音の有無として表現する場合が多いようです。
時間の表現
音楽を扱う以上、時間をどう扱うかというのも大事なポイントになります。大きく分けて、ステップバイステップで生成する方法と全体を一気に生成する方法が考えられます。
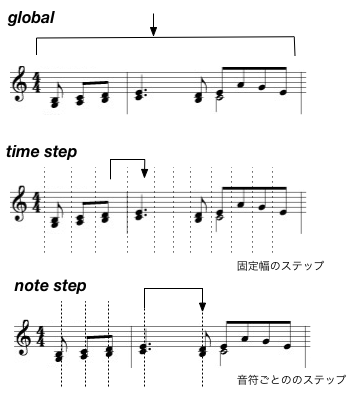
- グローバル global
一つの曲/フレーズ全体を一気に出力する方法. (この場合、モデルのアーキテクチャとしては、シンプルなFeedforward NetworkやAutoencoderが使われることが多く、Recurrent Neural Networkは使われません) - 時間を等分する方法 time step
時間を等分する方法です. ピアノロールの表現がそれにあたります. 通常は学習データのなかで最小の時間単位(たとえば16分音符)を単位として、その整数倍として時間を扱います。 - 音符ごとに扱う方法 note step
一般的ではないですが、決まった長さの時間の単位を持たない方法もあります。たとえば最近のGoogleのPerformance RNNでは、音ごとにピッチと強さにあわせてその長さを細かく(16分音符、8分音符…ではなく)指定してエンコードするようになっています(有限の選択肢の中からではありますが…)。
入力のエンコーディング Input Encoding
入力の表現が決まったとして、つぎにそれを実際にニューラルネットワークで扱える形式にエンコードする必要があります。ここでもいくつかの方式が考えられますが、次の二つが主流です.
- 数値として入力する方法
- one-hot ベクトルとして入力する方法
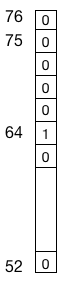
数値はわかりやすいですね。ピッチであれば、MIDIのピッチの数値をそのままつかったり、あるいはそれを0から1の間で正規化して扱います。二つ目のone-hotベクトルは機械学習の世界で一般的に使われる方法で、ピアノロールの考え方をそのままデータにしたものと考えてください。とりうる値が例えば0から9までの10個あるとしたら、10次元のバイナリのベクトルとして考え、0は[1,0,0,0,0,…], 1は[0,1,0,0,0…], 2は[0,0,1,0,0…] と言う具合に対応する次元のみ1、それ以外が0(ひとつだけ1なのでone-hotという名前があります.複数の1を許すk-hotエンコーディングを使っている論文もあります)であるようなベクトルとして考えます。
数値を直接使う手法は音声信号を扱う場合を除いてめずらしく、ほとんどがone-hotベクトルを使った実装になっています。数値を直接扱う手法があまり使われないのはは、繰り返し行う数値計算の結果、精度が落ちる = ノイズが乗りやすいのが一因です(アナログ信号とデジタル信号の違いを想像してください)。また、one-hotベクトルを使うことで、音楽の生成をある種のクラシフィケーションとして扱えることになります。次に来る音符として一番もっともらしいものを選択肢の中から選ぶという問題に置換できます。
データセット Datasets
Deep Learningのモデルの学習には当然大量のデータが必要です。自由に学習に使える音楽データの欠如がこの分野の発展を阻害してきた面がありますが、ここにきて少しずつパブリックなデータセットが増えてきているようです。
といっても… 筆者(徳井)の所感として、それらの音楽データセットの多くは、クラシック音楽等に偏っているように感じます(著作権が切れているからという理由が大きいとは思うのですが)。またその規模も、数百曲程度といったものがほとんどで、何百万といった単位のデータがある画像認識用のデータセットに比べて量においても見劣りします。良質で大規模な音楽データセットをどう構築するか、今後期待される研究領域の一つではないでしょうか。(データセットのリンク集をシェアしておきます)
移調 Transposition
規模が小さい音楽用のデータセットの欠点を補うためによく用いられるのが、移調 Transpositionです(MIDIやピアノロールのように記号で表された音楽の場合に限る) 。
画像認識モデルの学習時に、学習データの画像をすこし回転・拡大、あるいは反転したり、ノイズを意図的に載せることでデータを「水増し」する手法、Data Augmentationがよく用いられます。それと同様に、学習データにある曲を別のキーに移調することで、データ量を増やすという方法がよくとられています。こうすることでデータ量を増やすだけでなく、特定のキーのみにとらわれず幅広く学習できるといったメリットがあります。
アーキテクチャ Architecture
入出力について考慮末べき点がわかったところで、肝心の学習の中身をみていきましょう。実際にはどういったDeep Learningのモデルが用いられているのでしょうか。
1. Multilayer Neural Network / Feedforward Neural Network
一番一般的なニューラルネットワークですね。後に述べるRNNとくらべて時間の経過(時系列)を考慮しないので、一音一音生成するのではなくある入力に対して全体を出力するような使い方になります。

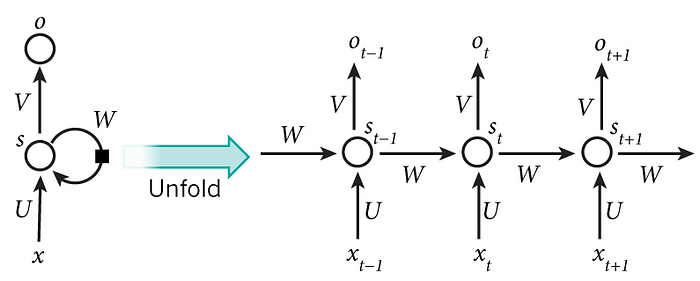
2. Recurrent Neural Network (RNN)
再帰型ニューラルネットワーク. 出力を入力に戻す再帰的なコネクションを設けることで、結果的に時系列データを扱えるようにしたニューラルネットワーク. 1とは逆に一音一音ステップバイステップで生成するような使われ方をします。その発展系であるLSTM(Long Short-Term Memory)として、RNNは音楽生成に広く用いられています。
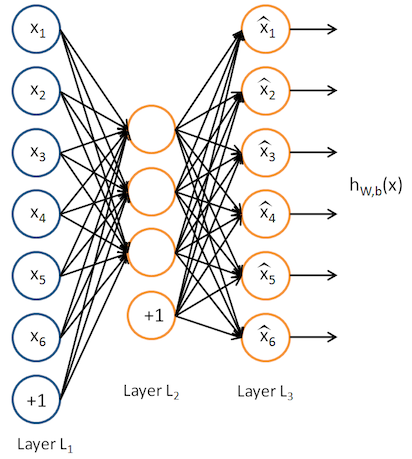
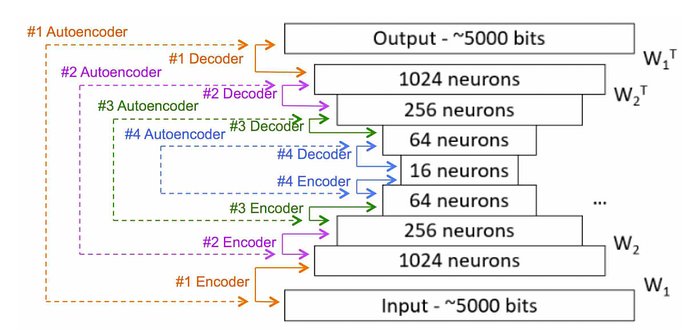
3. Autoencoder
「自己復号化器」という日本語訳が示すように、入力に等しい出力、入力を真似するような出力を出すように学習するニューラルネットワークです。通常は入出力よりも小さい次元の隠れ層を使います(下図中央のLayer 2)。こうすることで、学習データをより小さい次元で表現する=学習データ内のばらつきの本質的な部分を学習することが期待されます。
Autoencoderは音楽のコンテクストでもよく使われており、いままで人が手作業でつけていた音楽的な特徴量を、Autoencoderによって自動的に抽出できるようになりました。Autoencoderに考え方が近いものとして、Restiricted Boltzman Machine(RBM)やVariational Autoencoder(VAE)なども使われています。
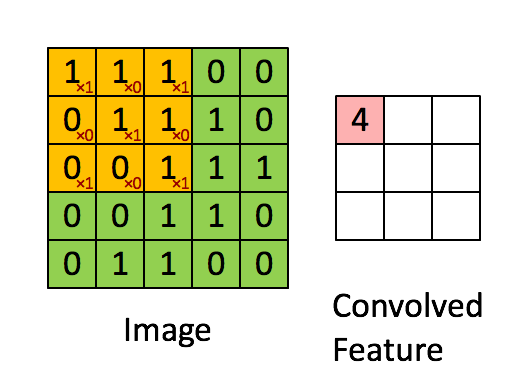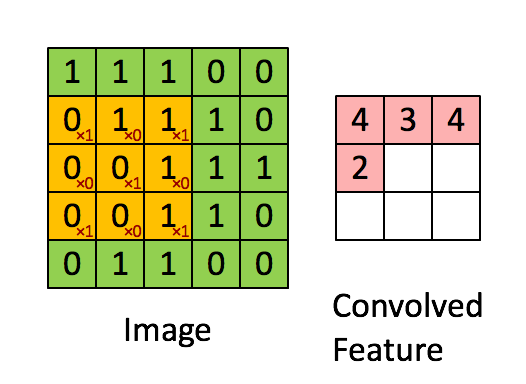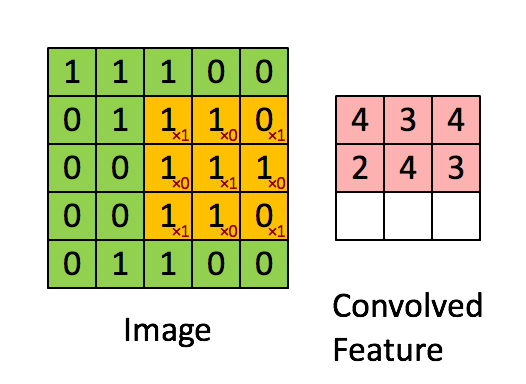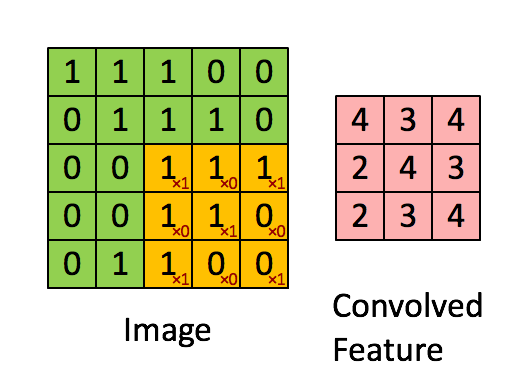
4. Convolutional Neural Network (CNN)
畳み込みニューラルネットワーク。画像認識などのタスクで広く用いられるアーキテクチャですが、音楽の生成にはこれまであまり多く使われてはきませんでした。時間軸方向に畳こむことで、時系列データを扱えそうなものですが、長期間の前後の依存関係を学習できるLSTMなどに比べると、CNNで畳込める時間方向の情報は限られています。しかしWaveNetが、Dilated Convolutionという手法によって長時間の依存関係を学習することに成功したこともあり(後述)、今後、CNNもより一般的に用いられるようになりそうです。
5. Generative Adversarial Networks (GAN)
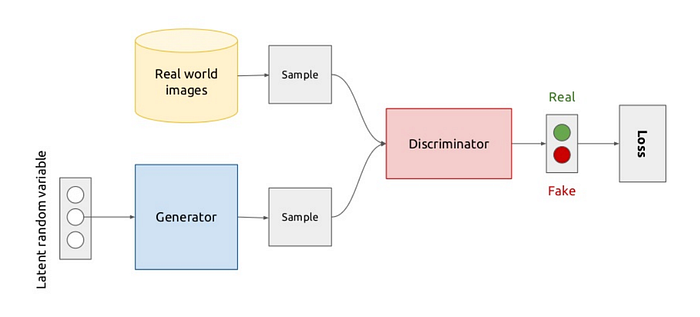
生成的敵対ネットワークという日本語訳よりもGANの方が馴染みが深いと思います。昨今話題のアーキテクチャ(といってもCNNやRNNとは違い、よりメタレベルのアーキテクチャ)として、GANに触れないわけにはいきません。学習データになるべく近いデータを生成するように学習するGenerator(生成器)と、生成されたいわば「偽物」と本物のデータ(学習元のデータ)を識別するDiscriminator(識別器)の二つのネットワークを互いに競わせるという画期的なアイデアをもとにしています。
画像の分野では、本物そっくりの顔写真を生成したり、pix2pixのように画像を変換したりといったタスクに広く使われていますが、音楽への応用はまだそれほど多くはありません。一つにはGANは安定的に学習させるのが難しい(Generator/Discriminatorのどちらかが賢くなりすぎて相手を騙せなくなってしまう)という点が指摘されています。GANを安定的に学習させる手法に関する研究が進むとともに、GANを用いた音楽生成も今後ホットなトピックになりそうです。
6. Reinforcement Learning (RL)
強化学習。環境からのフィードバック(reward 報酬)をもとに試行錯誤を繰り返すことで、モデル(agent)が学習していくという手法。ロボットの動作の学習など、昔から使われきた手法ですが、最近はDeep Learningに基づく強化学習の研究が進んでいます。Alpha Goなどが最も有名な例でしょう。
音楽にRLを使う例もまだそれほど多くはありませんが、今後応用が期待される領域です。リスナーやユーザ(たとえばAIといっしょに演奏するプレイヤー)からのフィードバックを受けながら、生成される音楽がすこしずつブラッシュアップあるいはナビゲートされていくといったかたちでの利用が想定されます。

7. 上記の組み合わせ
実際の研究の多くは上記のアーキテクチャを組み合わせたものを使っています。下記はその一例です
- RNN + Autoenoder
- RNN-RBM
- Convolutional GAN
- RNN GAN
実例 Systems
ここからは具体的な研究・システムの例を見ていきます。まずは一番シンプルなFeedforwardネットワークを使ったシステムから.
MiniBach System — 2017
Hadjeres, G., Pachet, F., & Nielsen, F. (2016). DeepBach: a Steerable Model for Bach Chorales Generation. Retrieved from http://arxiv.org/abs/1612.01010
バッハの多声の聖歌を学習、あるメロディーに対してバッハの聖歌風の伴奏を生成するというシステム。単純なFeedforward networkを用いています。入出力はone-hotベクトルとしてコーディングしたピアノロールの形式になります。最小の時間単位は16分音符。
356曲のデータセットを学習しました。入出力のノードは2800程度、200ノードの隠れ層からなるシンプルなネットワークです。入力の音符の列を入力すると、それに対する伴奏のメロディーが出力されるシンプルな構造です。これはあとに述べるDeepBachシステムの簡易版になります. (名前はmini-batchにかけているんでしょうか…)


Blues Melody Generation — 2002
Eck, D., & Schmidhuber, J. (n.d.). A First Look at Music Composition using LSTM Recurrent Neural Networks. Retrieved from http://people.idsia.ch/~juergen/blues/IDSIA-07-02.pdf
こちらはLSTMを使ってメロディーとコードを出力します。メロディー用に13のピッチと12のありうるコードをあわせた25ノードを入力と出力とし、隠れ層としてメロディー用に4つ、コード用に4つのあわせt8つのLSTMのユニットを用いたアーキテクチャです. (その前段階として、メロディーのみを生成するモデルも論文のなかではテストしています)
メロディー、コードそれぞれの入出力のノードはfully connectedされているうえに、コード用のLSTMのみ、メロディーの出力層ともつながっているのが特徴。こうすることでコードに基づいたメロディーの生成が可能になるというのが論文の著者の主張です。
学習データはブルース. 生成時には、シードとなるピッチ/コードを一つ入力するところから、あとを続けさせる場合と、数小節の入力を入力する方法、それぞれを試しています。いずれもブルースらしいフィーリングが再現できたとしています。一方で、コードの情報などを楽譜から読み解く手作業が必要になる、同じ入力に対しては常に同じ出力にしかならない(deterministic)といった欠点も指摘されています.
DeepHear 2016
Felix Sun. (n.d.). DeepHear — Composing and harmonizing music with neural networks. Retrieved November 21, 2017, from https://fephsun.github.io/2015/09/01/neural-music.html
次にAutoencoderとFeedforward Networkをつかったシステム、DeepHearを紹介します. Autoencoderによる音楽の高次の特徴を抽出。Autoencoderの隠れ層の出力にあたる乱数からを、デコーダーにあたるFeedforward Networkに入力することで、新たな音楽を生成します。
学習に使ったデータはラグタイムと呼ばれるジャズの源流になった音楽を600小節ほど。16分音符を最小単位として、4小節単位(したがって64タイムステップ)で学習しました。80ほどのピッチを取りうる値として制限することで、64x80で約5000次元のone-hotベクトルで入出力を扱います。autoencoderの学習は、いわゆるpre-training同様にレイヤーごとに行ったそうです。
学習が終わると、中央の層(エンコーダによって16次元にまで次元が削減されています)にランダムなシードを入力することでメロディーが生成されます。
生成されたメロディーに関しては、中央のレイヤーの次元が小さすぎた(16次元)が故?に生成される音楽がもとの学習元のデータに似通ってしまった、と著者らは分析しています。
https://soundcloud.com/deeplearning-music/deephear
deepAutoController 2014
Sarroff, A. M., & Casey, M. (2014). Musical Audio Synthesis Using Autoencoding Neural Nets. Proceedings of the International Computer Music Conference, (September), 14–20.
http://www.cs.dartmouth.edu/sarroff/papers/sarroff2014a.pdf.
上記のDeepHearに似通ったシステムですが、スペクトルを通してオーディオ信号を直接扱っているのが特徴です。ランダムなシードからだけでなく、ユーザインタフェースを通してユーザが直接入力されるシードの値をコントロールできるようにしています。学習に使った曲は10のジャンルの8000曲ほどです。下記のデモを見る限り出音はかなり実験的?!ですね。
DeepBach — 2016
Hadjeres, G., Pachet, F., & Nielsen, F. (2016). DeepBach: a Steerable Model for Bach Chorales Generation. Retrieved from http://arxiv.org/abs/1612.01010
すでに紹介しているMiniBachの拡張版です。同様にバッハの聖歌をあつかうのですが、feedforward networkとLSTMを組み合わせているのが特徴です。さらにこのLSTMは二つ用意されていて(200ユニット)、ある時点に対してその直前の音符/コードの情報を読むだけでなく、もうひとつはある時点から先の情報を逆向きに先読みするLSTMがあるのが特徴です。
これら二つのアウトプットはマージされ、feedforwardネットワークを通して次の音が選ばれます。(4声の聖歌を対象にしているので、このネットワークが4つあることになります)
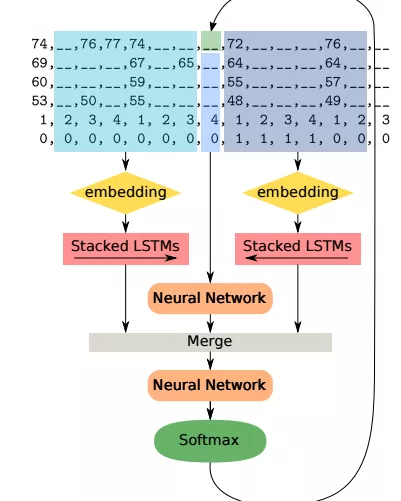
生成された音楽に対して1200人の被験者を用意して聞いてもらったらところ、本物のバッハの曲と区別するが難しいという結果がでたそうです。
Celtic Melody Generation — 2016
Bob L. Sturm and Joao Felipe Santos. The endless traditional music session, Accessed on 21/12/2016.
http://www.eecs.qmul.ac.uk/%7Esturm/research/RNNIrishTrad/
同様にRNNを用いた研究でケルト風の民族音楽のメロディーを生成するシステム。それぞれ512のノードをもつLSTMで、ABC記法によって表現された楽譜を学習します。ABC記法で対象となった楽曲を表すのに必要なアルファベットの数だけの次元のone-hotベクトルで入出力をエンコードしています。
Hexahedria Polyphony Generation — 2015
Daniel Johnson. (n.d.). Composing Music With Recurrent Neural Networks · hexahedria. Retrieved November 21, 2017, from http://www.hexahedria.com/2015/08/03/composing-music-with-recurrent-neural-networks/
Feedforward networkとRNNを組み合わせたユニークなアーキテクチャでポリフォニックなメロディーを生成するという研究。
4層の隠れ層を持ち、最初の2層がRecurrentな層(300ノード)、残りの2層(それぞれ100、50ノード)がfeedforwardなレイヤーです。RNNで時間方向の関係性を、Feedforwardであるタイミングで同時に鳴る音同士の関係=コードを学習するという目論見です。
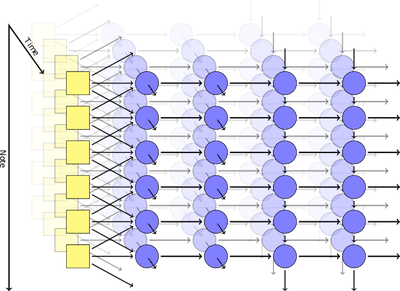
入出力はMIDIのピッチの値をつかったピアノロール形式. その音のクラス(C, D等)が直前に弾かれたかどうか、小節の中での位置などが補足情報として入力に追加されています。学習にはClassical Piano Midi PageのMIDIデータを利用しています。
VRAE Video Game Melody Generation — 2014
Fabius, O., & van Amersfoort, J. R. (2014). Variational Recurrent Auto-Encoders. Retrieved from https://arxiv.org/pdf/1412.6581.pdf
Variational AutoencoderにRNN(LSTM)を組み込んだ独自のアーキテクチャ VAREでTVゲーム風の音楽を生成する試み. RNNを二つ用意し、それぞれをエンコーダ、デコーダとして扱います。入力のフレーズを一通り入力したときのエンコーダのアウトプットと隠れ層の状態をデコーダに入力、その出力が入力と近くなるようにCross-Entropyの最小化を図ります。ここでエンコーダの出力をVAEの確率分布のパラメータ(μ, σ)として扱うのがポイントです(下の図のz)。
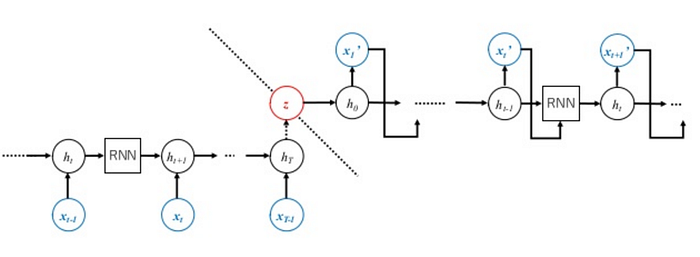
学習に使ったのは8つ(!!)の有名なゲーム音楽のMIDI. 49のピッチのみをあつかっているそうです。生成されたものを聞くと、かなり過学習しているようにも思えるのですが…何を学習したのかすぐにわかってしまいますね。
Maris et al’s — Rhythm Generation system — 2017
Makris, D., Kaliakatsos-papakostas, M., & Karydis, I. (n.d.). Combining LSTM and Feed Forward Neural Networks for Conditional Rhythm Composition.
このサーベイの中で唯一のリズムにフォーカスした研究。
データは45のロックのドラムとベースのパターンをそれぞれ16小節(http://www.911tabs.com/からダウンロード)。ドラムはキック、スネア、タム、ハイハット、シンバルの5種類をピアノロール形式で扱います(ピアノロールはバイナリーの文字列で表現)。ベースラインも学習データに入っているのですが、まず音符があるかどうかとそこでピッチが前の音から上がっているか、同じか、下がっているのか三つの値、この合計4個のバイナリで表現。さらに小節内での位置を3つのバイナリで表現したものも入力に追加します。
128、512のノードを持ったレイヤーを二つ重ねたLSTMを二つ用意し、一つにはドラムの情報(5個のバイナリ)、もう一つにベースラインと小節内での位置の情報(計7個のバイナリ)を入力します。それぞれの出力をマージしたものを最後のFeedfoward層に入力し最終的にSoftmaxを通してドラムの情報が出力されます。


ベースや小節内での位置の情報はドラムの生成モデルに対する条件付け(conditioning)の入力とみなすことができます。著者らはこの情報によって、学習効率と生成されるリズムの質が向上したと述べてます。
生成されたリズムの音源が見つからなかったのですが、上の図で見る限りはかなりシンプルなものにとどまっているようです。
WaveNet — 2015
Oord, A. van den, Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., … Kavukcuoglu, K. (2016). WaveNet: A Generative Model for Raw Audio. Retrieved from http://arxiv.org/abs/1609.03499
Google/DeepMindのチームによって開発されたオーディオ信号を直接扱うモデル。もともと音声合成の精度をあげるために開発されたモデルですが、音楽でもテストをしています。音声データをμ-lowというエンコーディングで8ビットの情報として扱い、256のとりうる値のうちで次のタイムステップでどの値が一番もっともらしいかという確率分布を出力することになります。

前にも述べたように、Dilated Convolution(正確にはある時点以前の情報のみをたたみこむ、非対称のDilated Causal Convolution) という考え方を導入することで一般的に長時間の時間依存関係を学習できないとされるCNNの問題点を回避しているのが画期的です。Dialated Convolutionは、レイヤーが上がる際にいくつかのインプットをスキップすることで上位に行けば行くほど広範囲をカバーすることになります。poolingやstrideと同じような考え方ですが、入力と出力のサイズが同じであるという点でDilated Convolutionはすぐれてます。学習にはMagnaTagATuneのデータセットの60時間を超えるピアノソロの楽曲を使っています
現在アルゴリズムの高速化が図られ、Google Assistantの音声合成の英語と日本語にWaveNetのアルゴリズムが使われているそうです。またWaveNetの技術を応用して、新しい音色を作り出すNSynthというプロジェクトも面白いです。
C-RNN-GAN Classical Polyphony Generation — 2016
Mogren, O. (2016). C-RNN-GAN: Continuous recurrent neural networks with adversarial training. Retrieved from http://arxiv.org/abs/1611.09904
ようやくここでGANをつかったシステムの登場です. ポリフォニックなクラシック音楽の生成を目的としたプロジェクトで、MIDIによく似た音楽の表現をとっています。MIDIと違うのは、前のイベントから時間のパラメータを持っていることです。Webで集めたクラシックのMIDI、3700程度を学習データとしています。
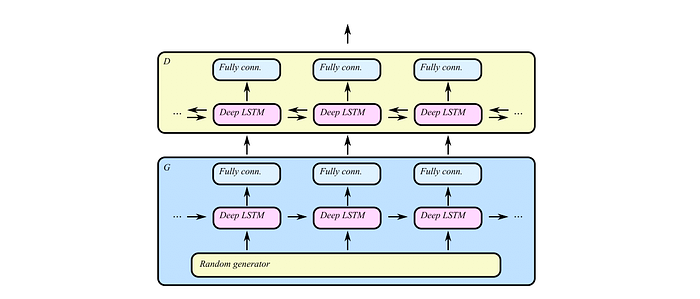
GANのGenerator, DiscriminatorはともにLSTMで350ユニットで2つのレイヤーを持っています. Discriminatorのみ、順方向・逆方向(先読み)の両方の情報を入力するようにしなっています.
GANの学習を安定化させると言われるfeature matchingの手法がここでも有効だったと報告されています。
MidiNet — 2017
Yang, L.-C., Chou, S.-Y., & Yang, Y.-H. (2017). MidiNet: A Convolutional Generative Adversarial Network for Symbolic-domain Music Generation using 1D and 2D Conditions. Retrieved from http://arxiv.org/abs/1703.10847
上記と同様にGANの構造ですが、RNNではなくCNNを使っています。1022のポップスのメロディーを学習しています。2オクターブの範囲で時間の最小単位が16分音符としてピアノロールのフォーマットで表現しています。またone-hotベクトルで表現したコードの情報を条件付け(conditioning)の入力として使っているのも特徴です(下の図の左上の青で表現)。
Generator, DiscriminatorともにCNNの構造で、ちょうど対称になるような構造になっています。Generatorが2層のfully connectedレイヤーとそれに続く4層の畳み込み層からなるのに対して、Discriminatorは2層の畳み込み層のあとにfully connectedレイヤーが続きます。
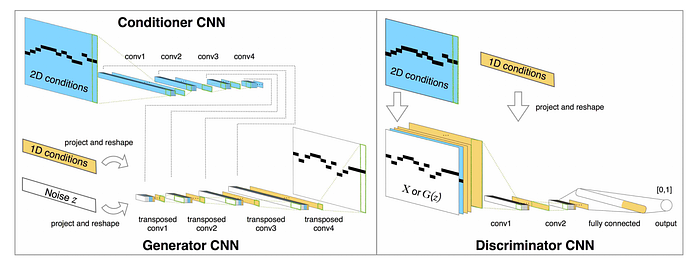
論文の中では、コードの情報の条件付けが有効に働いているということが検証されています。また、feature mathcingのパラメータをコントロールすることで、どのくらい元の学習データに近いものを生成させるか、裏を返せば、どのくらい生成の自由度を与えるかをコントロールできるのではという提案がなされています。”Creative” Adversarial Networkの研究のような、Computational Creativityの本質に関する議論にも関わってきそうな提案です。
RL-Tuner Melody Generation System — 2016
Jaques, N., Gu, S., Turner, R. E., & Eck, D. (n.d.). TUNING RECURRENT NEURAL NETWORKS WITH RE- INFORCEMENT LEARNING. Retrieved from https://arxiv.org/pdf/1611.02796v2.pdf
音楽の生成を強化学習(RL)の問題として定義した研究. システムは少し複雑で二つのRNNと二つのDeep Q-Networkから成り立ってます。最初に上述のBluesのメロディー生成のシステムと同様に次の音符を予想するRNN(Note RNN)を学習。そのコピーをRLに対して報酬(reward)を与えるネットワークとして利用します(Reward RNN)。同様にQ-Networkのタスクは、それまでの音符から次の音符を選択するタスクとなりますが、このQ-NetworkはもうひとつのQ-Network(Target Q Network)がNote RNNが学習済みの情報に基づいてgainを予想することで学習できます。
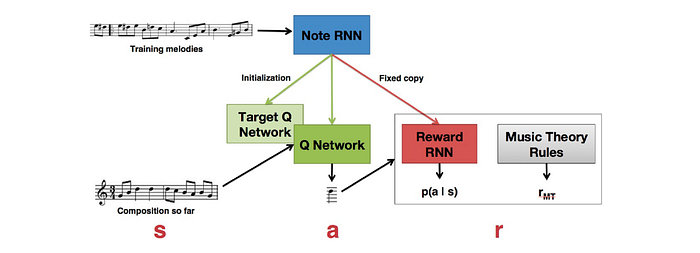
Q Networkの報酬は、Reward RNNが予想する音にどのくらい近いかだけではなく、ユーザが付け加えた制限(たとえば音楽理論やコードを指定するなど)も加味して計算されます。したがって、Q NetworkはRNNによって学習した内容だけでなく、ユーザのコントロールにも従うことになります。
Unit Selection & Concatenation Melody Generation — 2016
Bretan, M., Weinberg, G., & Heck, L. (2016). A Unit Selection Methodology for Music Generation Using Deep Neural Networks. Retrieved from http://arxiv.org/abs/1612.03789
既存のメロディーの断片をつなげる(concatenate)ことで新しいメロディーが生成できるのではという珍しいタイプの研究です. 音素をつなげていくことで一連の音をつくるという、今も広く使われている音声合成の手法から発想を得ていると思われます。
ここでつなげるメロディーの単位は一小節。ジャズやロック、クラシックなど4200程度のリードシートと120のジャズのソロの情報をデータセットとして用います。あらかじめ移調しておくことで特定の音域に偏らないようにします。
アーキテクチャーとしてはまずはRNNをもちいたAutoencoderを使います。手作業であらかじめきめておいた10個の特徴量を、データセット内の各小節にたいしてbags-of-words(BOW)の手法で数えておきます。特徴量としては、音のクラス(CやD, etc)の数や、最初の音が直前の小節とスラーでつながっているか..などなど。結果的にば9675のバイナリの特徴量になります。Autoencoderはこの入力から、500次元にまで削減したうえで、再度9675次元で出力します。これによって各小節が500次元のembeddingで表現されることになります(左下の図の緑の部分)。


この学習がすんだところで、実際の生成にはいるわけですが、ここでは二つの要素が考慮されています。
- 連続する小節の関連性の高さ (semantic relevance)
LSTMのネットワークを別途用意して、上記の500次元で表現されたベクトルの連続性を学習します. 128ユニットのLSTMレイヤーが二層、入出力は512ノード(あれ500じゃないの??)。入力に対して次の小節が持っているべき特徴を出力することになります。 - 連続する音のもっともらしさ (concatenation cost)
前の小節の最後の音と次の小節の最初の音の関係のもっともらしさ。各音はとりうるピッチと長さの情報を元に3000次元のone-hotベクトルとして表現され、LSTMによってその関係を学習します.
こうして計算された二つのコストから、前の小節に続く次の小節として一番もっともらしい小説が選ばれ、つなげられていきます。
考察・今後の展開
最後にここまで見てきたシステムの実例をもとに、Deep Learningを用いた音楽の生成手法の現状と筆者(徳井)が考える今後の展開について総括したいと思います。
現状
日進月歩で研究が進んでいる画像の生成モデルの研究に比べて、音楽の生成モデルの研究は質・量ともにだいぶ見劣りがするという印象をうけました。もちろん市場のニーズの影響が大きいのは間違い無いと思うのですが、学習に使えるデータセットがまだまだ未整備であるというのも理由の一つではないでしょうか。また個人個人の好みが大きく異なる、映像以上に不協和なものに対して敏感であるといった音楽ならでは特徴も影響しているのかもしれません。
また現状の研究の多くが、従来のコンピュータ音楽の研究領域で扱われてきた楽譜と音楽理論をベースにした研究の延長線上にあり、それらによって扱いやすいクラシックやジャズを対象にしているものが多いようにも感じています。今後、その他のジャンルにも研究が広まるためにも、データセットの拡充は必須であるようにも思います。
研究を進めるためには、社会のニーズという観点は避けて通れません(もちろん、僕自身は新しい音楽を作りたいという純粋な欲求こそがこういった研究を推し進める究極的な原動力だとは思っているのですが…)。AIが生成された音楽に対するニーズという観点から考えてみるのも良いのかもしれません。
すこし脱線しますが… Spotifyで一番聞かれているプレイリストのうちのいくつかは、「寝るための音楽」とか「集中したいときの音楽」のような特定の機能性をうたうプレイリストなんだそうです。匿名性が高く(誰が作ったかは問わない)、その「効能」によって評価しやすいこれらの音楽が、AIと相性がよいことはすぐに想像がつきます。実は今回参考にしたサーベイを書かれたF.Pachetさんは、最近Spotifyの研究所に移籍されたそうです。近い将来、気づかない間にAIによって生成された音楽を聞かされてる...なんてことになっているかもしれません。
もう一つの軸は、人が聞く音楽ではなく、「機械が聞く」音楽を生成するという観点です。画像生成モデルも、画像認識エンジンの精度を上げるために生成モデルによって生成した画像を学習に使うことが提案されています。同様に音楽の識別モデルの精度を高めるために、生成モデルがつくった曲を使うというのも需要がありそうです。
今後の研究のフロンティア
今回のサーベイで一番意外だったのは、GANをつかった研究がかなり少ないということでした。2016–2017年はGAN一色といっても過言ではないくらい、主に画像の生成を中心にさまざまな研究が話題になりましたが、音楽の方への応用はまだまだ少ないようです。ひとつにはGANならではの学習の難しさというのもあるのかもしれません (自分でもGANでのリズムの生成を試して見たのですが学習がまったく安定しませんでした…)。また楽譜で音楽を扱っている限りは、解空間が(画像以上に)離散的にならざるをえないというのも学習を難しくしているのかもしれません。
同様に、WaveNetのように音声信号を直接扱う手法についても今後の研究が期待されます。計算の処理が重いという問題がありますが、楽譜などのシンボリックな表現の制限を受けないことで、新しい音楽領域・ジャンルへの応用が期待されます。またより連続的な解空間を持つという利点もあるのではないでしょうか。
もうひとつ今後重要になってくるのは、そもそもなんのためにAIで音楽を作るのかという視点です。「バッハのような」あるいは「ビートルズのような」音楽を生成することが目的でよいのでしょうか。そうした視点からもシステムの製作者があらかじめ定めた、アプリオリな評価関数を持たないGANのような手法がひとつの突破口になりそうです。
サーベイ論文の中でも取り上げられている、Creative Adversarial Networkの研究がひとつの参考になります。二つのDiscriminatorを持つGANのバリエーションで、新しい抽象画を生成しようという研究なのですが、生成された絵が学習元のデータセットにある絵画に近いかどうかを判定する通常のDiscriminatorとは別に、その絵を過去の歴史上のジャンル(印象派・キュビズム etc)に分類するDiscriminatorを用意します。そしてどのジャンルにも「あてはまらない」ものを高く評価することで、「アートらしさ」と「新規性」のバランスをとったより創造的な作品を生成できるとしています。

同様の考え方で、誰も聞いたことのないような音楽を生成するシステムを構築できるのか。ひとつ大きなチャレンジが目の前に横たわっているように思います。
もう一つの方向性としては、全自動で音楽を生成するかわりに、生成の過程に人間をうまく絡めていくという考え方もあるでしょう。なんらかのユーザインタフェースで生成の方向性をナビゲートする、人間の伴奏者と掛け合いを行う、リスナーの評価(生体信号??)を生成のロジックにフィードバックするなどなど、いくつかのバリエーションが考えられそうです。これはDeep Learning以前のコンピュータ音楽の研究でも広く研究されてきたトピックですが、Deep Learningの登場でそういった分野にどのようなアップデートがなされるのか、興味を惹かれるところです。
AIを用いた自動作曲を売り物にするスタートアップやその技術に関する言及がまったくなかったことに気づかれた方もいらっしゃるでしょうか。彼らがAIで「生成」したと語る音楽はここで紹介したものよりもより完全な「音楽らしい」音楽です。 スタートアップなので技術的な詳細が明らかになっていないというのもありますが、限られた情報や生成された楽曲から推測するに、彼らの仕組みはある種のルールベースに基づいたもので、大量のループをルールに基づいて組み合わせていくことで楽曲をかたちづくっているようです。その一部にDeep Learningが用いられている可能性もありますが、使われ方は限定的と考えてよいでしょう。AIによる音楽生成といった記事を見たときにすこし念頭においておくとよいかと思います。
最後になりますが、すばらしいサーベイを書かれたJean-Pierre Briot氏、Gaëtan Hadjeres氏、François Pachet氏のお三方に感謝の意を表します。
