2019.9.20 update: 本記事で紹介している曲が Spotifyで公開されています!
今回はここ半年ほど取り組んでいる、Deep Learning/機械学習を用いた音楽制作についての個人的なメモです。考え方の背景から技術的に工夫したところ、今後のビジョンなどについて書きたいと思います。(先に実際に作った曲を聴いてみたい、という方はこの記事の一番下まで飛んでください!)
自己紹介
まずは自己紹介を。私は2019年4月から慶應義塾大学SFCにて、Computational Creativity、AIと創造性、特に音楽に関する研究室を主宰する予定です。この記事はSFCの学生(および未来のSFCの学生)に向けての文章という意味合いもあるので、すこし丁寧に自己紹介します。

私は大学で人工知能・人工生命などの研究を行っていた学生時代にDJを始めました。会社(Qosmo)を始めてからというもの、以前に比べて回数は減ってますが、いまも二ヶ月に一度くらいはなんだかんだでやらせてもらっているでしょうか。
ジャンルはテクノとハウスの中間の領域を幅広くかけるスタイルだと自分では思っています。
AIのDJとのBack to Backを行うAI DJ Projectを始めてからというもの、特にその雑食性が強くなっているかもしれません(なんせ、今作っているAI DJにはジャンルという明確な概念がないので、人がかけないような意外な選曲をすることが多いからです)。一方で、自分がDJでかける曲を中心に曲作りもDJを始めたころと時期を同じくして始めています。PROGRESSIVE FOrM, op.discといったレーベルから、実験的なダンスミュージックをリリースしたり、故Nujabesとも実験的な曲を共作したりしています。特にアルバム”Mind the Gap”を出した2003年前後は、人工知能(厳密に言うと進化計算)の手法を用いた音楽制作についての研究を、自分の博士論文のテーマの一部にしていたこともあり、音楽の世界に完全にどっぷりつかっていました。
背景 — マイクロサンプリング
その当時、特に自分が強く影響を受けていたのが、エレクトロニカと呼ばれていたジャンルです。Apple PowerBook G3が発売され、オーディオの処理がラップトップでできるようになった(それ以前はオーディオをコンピュータで扱うのが難しかったなどと言うと、今の学生さんはみなびっくりしますね。)、Cyclyng’74 Max/MSPのような音楽プログラミング環境が普及した、などさまざまな出来事のタイミングがそろったからでしょうか、実験的な音を使いつつも、ポップにそして時にダンサブルな音楽が世界中で同時多発的に生み出されていきます。日本でもSilicom/AOKI takamasaらが彗星のようにシーンに登場します(同じ時期にパリに住んでいたということもあり、同い年のAOKIくんとはのちに大の仲良しになります)。
そんな中、エレクトロニカの手法を、よりクラブミュージックに近い領域で応用する動きも出てきます。特に当時の僕が強い影響を受けたのが、Akufen, Jan Jelinek, Prefuse’74らのアーティストでした。
(この三つがすべて2001年だったということにこの文章を書いていて初めて気づきました。)
特にAkufenは、ラジオなどの音源を大胆にカットアップし、短い音の断片をつなげていくというスタイルで、マイクロハウス(Micro House)あるいはクリックハウス(Click House)と呼ばれる新しいジャンルを確立しました。全く異なるコンテクストの音の断片で独特のグルーブ感、世界観を提示していました。異なる性質の音を上手に音階に並べることで、メロディー構築していく手法も特徴的だったといえるでしょう。
マイクロハウスはインターネット以降のデータベース化していく社会を反映していた、というとちょっと大げさでしょうか。ただ、当時の自分の気分を間違いなくとらえた音楽でした。
彼らの音楽に魅了されてからというもの、なんとかして自分なりの手法で彼らの音楽をアップデートできないか、技術的な工夫で彼らも作れなかった音楽が作れるんじゃないか(おこがましいですが)というのが、頭の片隅にずっとありました。
同じようなことを考える人はヨノナカにはたくさんいたようです。2006年の学会でのこのパフォーマンスの映像を見たときは、やられたと思いました。
あらかじめ用意したミュージックビデオの断片と自分がマイクを通して入力した音を、リアルタイムにスペクトログラムで比較することで、入力したビートボックスがミュージックビデオで再構成されます。(このプロジェクトの名前がどうしても覚えられず、今でも検索しようとするたびに苦労します)。
またTristan Jehanさんは機械学習によるサンプリングをベースにした作曲手法についての研究をMITで行い、”Creating Music by Listening”という論文で博士号を取得しています。彼が中心になって立ち上げたEchonestという音楽解析に特化したスタートップは、その後Spofityに買収され、みなさんが聴く音楽のレコメンデーションの基礎として使われています。(今もSpotifyのAPIを使えば、Echonestで解析した音楽の特徴 - 踊りやすさ、曲調の明暗、ビートの強度 — などを取得することも可能です。)
今回のプロジェクトのスタート
ひるがえって僕自身はというと。。。ずっとアイデアだけはためていたのですが、なかなか実行に移すことができないでいました(ブラウザ上でMashupを作るソフトウェアなどを作ったりはしてました)。その後、2016年に始めたAI DJ プロジェクトによって、転機が訪れます。AI DJプロジェクトは、AIのDJと自分が一曲ずつ曲をかけあい Back to BackでDJをおこなうというプロジェクトです (AI DJ プロジェクトについての記事)。

DJの基本は、音楽の流れをとぎれさせないこと、前にかかっている曲の曲調をうまく引き継ぎつつ、絶妙なレベルでの意外性を選曲に持ち込む、そこにDJの選曲の技量が試されます。そこでこのプロジェクトでは、Deep Learningのモデルを用いて、音楽の「雰囲気」を定量化するということをやりました。
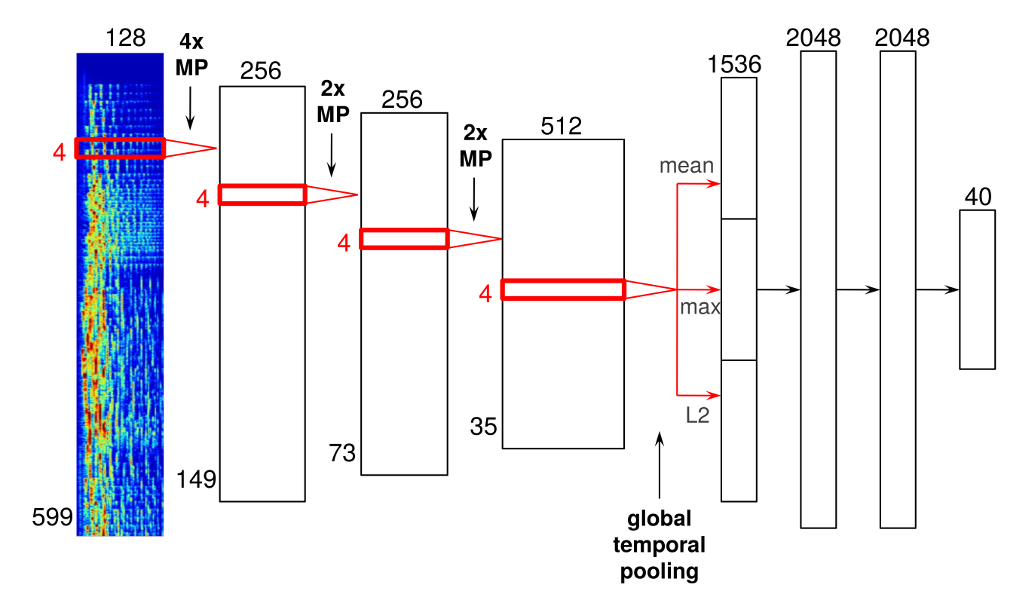
その中で音からその曲のジャンルを推定するというモデルを学習しています。もしジャンルが推定できるのであれば、楽器を推定したりできるのではないか、大量に集めた音の中から、ピアノっぽい・トランペットっぽい音だけを、あるいは波の音だけを拾い集めたりといったことが自動でできるのではないか、そんなことを考え始めました。さらにピッチ(音高)も解析すれば、猫の鳴き声だけでピアノのオクターブを網羅するといったことも可能なのではないか… と。
Keunwoo Choi, Gyrgy Fazekas and Mark Sandler. Transfer learning for music classification and regression tasks. Mar 2017.
そんなことを考えてまず最初に作ってのがNeural BeatboxというWebサイトです。ブラウザ上で音を録音しアタック(打点)で複数のパートに分割、ドラムの楽器のデータセットで学習したモデルでドラムキットを作ります。この部分はキックに似ている、ここはスネア、こっちはハイハットっぽく聞こえる、というわけです。こうしてできた即席のドラムキットでドラムのパターンを奏でます。ドラムのパターンもDeep Learningのモデルで生成しています。ヒューマンビートボックスを自動生成するようなイメージでしょうか。(この時はリズムの生成にはGoogle MagentaのDrumRNNのモデルを利用しました。Tero ParviainenさんのNeural Drum Machineのソースコードを利用させていただいています)
楽器認識モデル
この仕組みがある程度うまくいったことを良いことに、次は楽器の識別のモデルも同じような方法で作ってみたのですが、こちらはあまりうまく行きませんでした。マイクの前で録音してもらう場合と違って、当たり前ですが、音楽ではさまざまな楽器が同時に鳴っています。一つの楽器しか鳴っていないというパートは少なく、うまく解析することができませんでした。
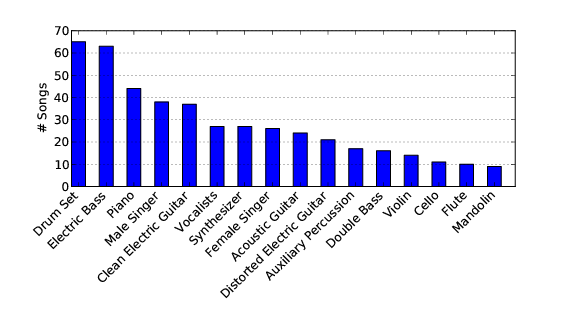
そこで今度は複数の楽器が同時に鳴っているときに、その複数の楽器を推定するモデルを作ることを試みました (Multi-instrument recognition) 。ありがたいことに楽器の推定を学習するためのデータセットが公開されています(MedleyDB)。MedleyDBでは、マルチトラックの曲に対して、それぞれの楽器ごとトラックとそれらをミックスした楽曲の両方、さらに各トラックの音量が記述されたcsvファイルが公開されています。このデータを使って楽器を識別するモデルを学習することで、”このパートにはオルガンとボーカルが入っていて、それぞれ70%、20%の確度”、というのが推定できるようになります。
Gururani, S., Summers, C., & Lerch, A.. Instrument Activity Detection in Polyphonic Music Using Deep Neural Networks. (2018)
Hung, Y.-N., & Yang, Y.-H. FRAME-LEVEL INSTRUMENT RECOGNITION BY TIMBRE AND PITCH. (2018)
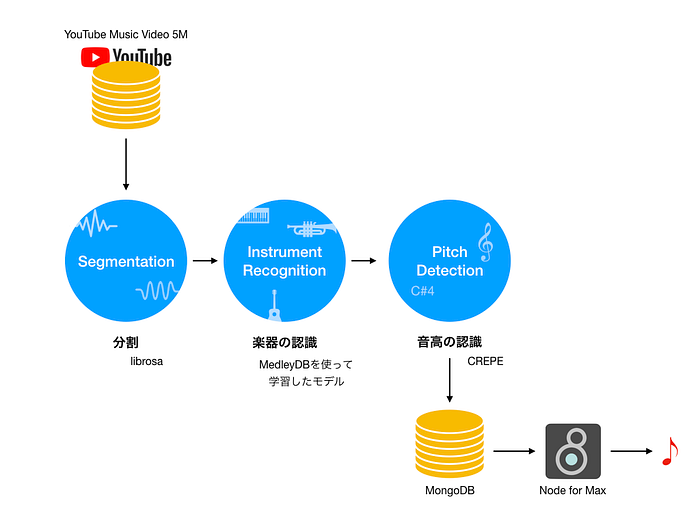
あとは肝心のサンプリング元、素材となる音のデータをどうするかですが、ここではYouTubeから集めることにしました。将来的に、sCrAmBlEd?HaCkZのようにビデオと合わせたパフォーマンスをやれれば、と漠然と考えていたというのがその一番の理由です。さらにSpotifyの研究所に所属するKeunwoo ChoiさんがYouTube上のミュージックビデオ、500万曲分のURLを研究用に集めたリスト YouTube-music-video-5M を公開してくれていたのも大きかったですね。
あとはこのリストにあるビデをひたすらダウンロードし(5日くらいかかったように記憶しています)、音だけを抽出、アタックで切ってセグメント分けを行い、上記の楽器の解析にかけます。さらに同じくDeep Learningを使ったピッチ推定のアルゴリズムにもかけました (畳み込みニューラルネットワークを使ったモデル)。ピッチ自体はDAW上であとでいくらでも変えられるのはたしかなのですが、元の音のピッチを使うことにここではこだわりました。
推定した楽器の情報は、そのファイルのパスとその区間の始まり/終わりの情報とともにいったんローカルのデータベース(MongoDB)にすべて格納します。データベースからの呼び出しは、最近リリースされたMax8の新機能、Node for Maxをつかっています。Node.jsの機能をMaxから使えるようにしたというNode for Maxを使うのは今回が初めてでしたが、その便利さに驚きました。今回のように大量のデータをMaxの中で扱いたいという場合に、Node for MaxをつかってDBにアクセスするというやり方は今後もいろいろと使えそうです(しかもnpmをつかって簡単に環境を他のマシンに移植できるというのも便利)。
リズム生成
これでメロディーや上ものを乗せる準備はできました。あとはリズムですが、リズムもやはりDeep Learningで生成することにしました。MagentaのDrumRNNもよくできているのですが、いかんせんvelocity(強さ)の概念がない、16分音符のグリッドにきっちり乗ったリズムしか生成できない という決定的な欠点があります。グルーブ感のあるリズムを生成するには、強弱はもちろん、微妙なリズムのタメ(=グリッドからのずれ)が重要になります(J Dillaがクオンタイズを嫌ったのは有名な話)。そこで今回はVariational Autoencoderを使ったドラムパターンの生成モデルを作ってみました。
Borghuis, T., Tibo, A., Conforti, S., Canciello, L., Brusci, L., & Frasconi, P. (2018). Off the Beaten Track: Using Deep Learning to Interpolate Between Music Genres. Retrieved from http://arxiv.org/abs/1804.09808
このモデルでは、ベロシティーを含めたリズムのパターンを出力するだけでなく、各打点のグリッドからのズレ(つんのめり気味・遅れ気味)をも併せて出力するようにしました。
ベロシティー/ズレのあるなしで聞き比べてみると、その重要性が明確になるかと思います。
このリズムの生成の仕組みは2019年2月にYCAMで発表したダンス作品”Israel & イスラエル”でも、フラメンコのステップのリズム(サパテアード)を生成するために大いに活用されました。
こうしてリズムを生成した上で、先に述べた機械学習マイクロサンプリングでメロディ的な要素を足してきました。リズムにハードウェアのRoland TR-08, ベースラインはAbleton Liveに付属するソフトシンセを使っている以外は、すべてYouTube 5Mのミュージックビデオからサンプリングした音になります。打ち込んだMIDIシーケンスをループ再生しつつ、自分が設定した条件のなかで何度も何度もランダムにサンプルをキーボードにアサインする行為を繰り返しながら、面白い音になるサンプルの組み合わせを探すという過程を経ています。
完成曲
こうしてできた曲がこれです。楽器の識別モデルでVocalとして認識された音を中心に使ったので、タイトルを”Vox YouTube Populi” (Vox Populi = 民衆の声) としました。
今後の展望 & まとめ
ここでは音楽の良し悪しを問うことはしません🙂 もちろん聴く人の好みが評価を左右することでしょうし、自分もAkufenをアップデートできたとはとても思えないです(逆にAkufenのセンスがいかに素晴らしかったかを痛感しているところ) 。
一方で、(人手で処理するのはかなり難しいくらいの)大量のサンプルを使いつつも自然な感じに聞かせることができたとは自負しています。それは、楽器の認識や音高(ピッチ)の認識をきちんと行ったからでしょう。その過程の中で、自分でもドキッとするような、サンプルの組み合わせ、メロディーが生まれてきました。
以前、Deep Learningを使った音楽生成に関する研究をまとめた記事を書きました。
Deep Learning Techniques for Music Generation — A Survey
Jean-Pierre Briot, Gaëtan Hadjeres, François Pachet
この記事で紹介した研究のフォーカスは、Deep Learningのアルゴリズムそのものにあります。したがって、アルゴリズムのアウトプットがそのまま最終的な音楽として提示されている場合がほとんどです。
一方で、今回私が試したかったのは、これらのアルゴリズムをあくまでも音楽制作のツールとして利用し、実際に新しい音楽を作ることにチャレンジしてみるということです。研究としての厳密さは二の次で、結果として新しい面白い音楽ができるかどうかにだけ、注意を払ったつもりです。
少なくともAIで音楽を作るといった場合に、楽譜やMIDIそのものを生成する以外にも、いろんな使い方があるということがこの記事を通して伝わればうれしいです。またこういう使い方ができる学生が自分の研究室から育っていけば、日本の音楽シーンももっともっと面白くなるんじゃないか、そんなことを考えています。
以前いっしょに仕事をさせていただいたBrian Enoさんは「自分はArtificial Intelligenceではなく、Artificial Stupidityに興味がある」とおっしゃっていました。人工的な愚かさとでも訳せばいいのでしょうか。過去に人間が作ってきたもの、過去の名作が正解だとするならば、「間違い」「愚かさ」にこそ、新しい表現のタネがある、というわけです。
その際、ただランダムなだけでは意味がありません。過去の音楽のパターンを踏襲しつつ、賢くパターンから逸脱する、賢く間違いを犯すシステムが好ましいわけです。そういう意味で、「Artificial Intelligent Stupidity」が正しい表現なのかもしれません。
今回の取り組みは、このAISを使った音楽制作の第一歩です。今後、自分のSFCでの研究室を中心に、新しい音楽の作り方について、どんどん試していきたいと考えています。興味がある学生はぜひ僕の研究会 Computational Creativity — X Music に参加してください。賢い間違いにこそ意味があるというのは、音楽以外でも人間の創造性を考える上で、重要な観点だと思っています。AIと人間の創造性の関係をアルゴリズムの部分から考えていくもうひとつの研究会Computational Creativity — AI and Creativityも開催します。内容としてはオーバーラップしていますが、初年度はこの二つの研究会を持つので、自分の興味に合わせて選んでいただければと思います。
余談ですが、今回、数年ぶりに自分のためだけに曲を作りました。久しぶりに音楽制作の面白さを改めて感じているところです。今年中にもう少し曲をまとめてレコードをリリースする、そう宣言してこの記事を終わりにしたいと思います 😉
